실험 순서
- Baseline (Image+Text 모두 FP32)
- 이미지 인코더만 INT8 양자화
- 텍스트 인코더만 INT8 양자화
- 둘 다 INT8
1: Baseline 측정 (Image + Text 인코더 모두 FP32)
- 이미지 인코더와 텍스트 인코더 모두 FP32 상태에서,
- 이미지 ⟶ image encoder ⟶ image feature
- 텍스트 ⟶ text encoder ⟶ text feature
- 두 feature 간 cosine similarity or matching score 측정
dataset_ms_split_1.pkl과 dataset_ms_split_2.pkl은 각각 전체 데이터셋의 “절반씩 분할된 버전”
→ “split 1 + split 2 = 전체 MSP60K”
원하는 흐름
- dataset_ms_split_1.pkl과 dataset_ms_split_2.pkl 모두 불러옴
- 각 pkl에서 trainval과 test 인덱스 가져옴
- 모든 인덱스 합쳐서 중복 제거
- 해당 인덱스로부터 image_name 추출
- 기존 코드대로 CLIP 모델로 이미지 인퍼런스 수행
원본 이미지 크기가 커서(총 1GB 정도) 제공해준 degrade image 버전으로 진행했다.(총 650MB 정도)
Baseline Model(CLIP)

TinyClip

MobileClip

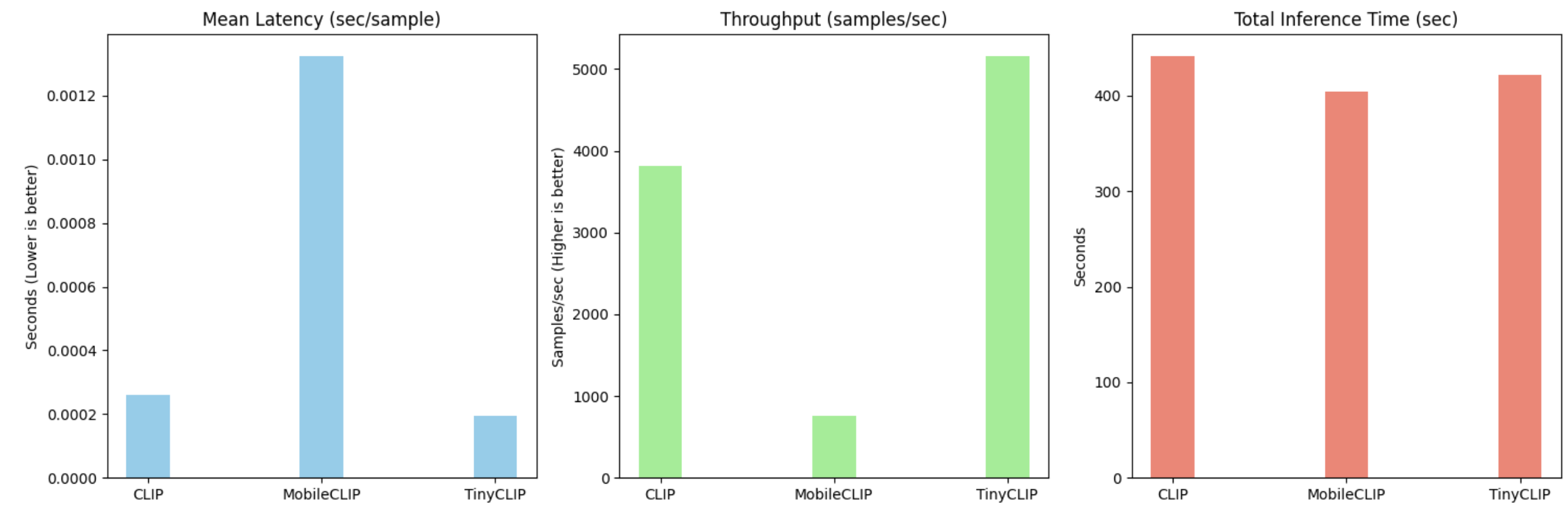

- TinyCLIP이 압도적으로 가장 낮은 latency와 가장 높은 throughput 보여줌. 총 inference 시간도 짧은 편
- CLIP은 latency는 중간이고 throughput도 높지만 총 시간은 제일 길었음
- MobileCLIP은 latency 가장 높고 throughput은 낮음
degrade image로 진행
- 앞으로 모든 실험 (quantization 포함) 동일 조건 유지할 것
- 논문에 사실 명시할 것
1. 일관성 유지
앞으로 할 모든 실험 (4bit 양자화, dual encoder quant 등등)도 baseline과 동일한 입력 이미지로 진행해야 공정한 비교 가능
2. degrade = 실제 Edge 환경 모사
실제 Edge 디바이스에서는 해상도 낮거나/ 압축 이미지나/ 라이트한 입력 처리가 기본값
3. 속도, 메모리, GPU 효율 측면에서 이득
원본 1GB vs degrade 650MB -> 모델 인퍼런스 뿐만 아니라 전처리 속도 + I/O 비용 줄어듦
현 상태
- dataset_ms_split_1 + 2 → 인덱스 중복 제거해 통합(전체 60,122장 실험)
- CLIP model & processor → openai/clip-vit-base-patch32 사용
- GPU에서 인퍼런스 시간 측정
- feature 저장, latency 로그 저장
진행 예정
- Image encoder 양자화 (4bit or INT8)
- 일단 PyTorch native quantization으로 시작
- 가능하면 bitsandbytes, torch.ao.quantization, nncf도 고려
- 양자화된 encoder로 위와 동일한 인퍼런스 반복
- clip_image_features_quant.pt, latency_log_quant.txt 저장
- 정확도 체크 (mAP, F1, Recall 등)
- 향후 비교용으로 baseline vs quant 성능 대비
'Capstone' 카테고리의 다른 글
| [ Meeting ] 5월 2주차 - 정밀도 낮추기 실험 (0) | 2025.05.12 |
|---|---|
| 이쯤에서 다시 보는 목표 (0) | 2025.05.09 |
| [ Meeting ] 4월 3주차 - Quantized clip 조사, Baseline 성능 측정 (0) | 2025.04.17 |
| [ Meeting ] 4월 2주차 - 데이터셋 구성, 모델별 Inference Time 측정 (0) | 2025.04.11 |
| [ Meeting ] 4월 1주차 - 경량 CLIP 모델 선정 및 실험 환경 최적화 (0) | 2025.04.07 |


