https://onnxruntime.ai/docs/performance/model-optimizations/quantization.html?
Quantize ONNX models
ONNX Runtime: cross-platform, high performance ML inferencing and training accelerator
onnxruntime.ai
ONNX 동적 양자화 (Dynamic. Quantization)
특징
- 가중치(weight)만 INT8로 양자화되고 활성값(activation)은 FP32 상태로 남아 있음
- 모델 쉽게 변환할 수 있고, 캘리브레이션 데이터 필요 없음
- CPU 실행 기준으로 최적화되어 있음
장점
- 빠른 적용 가능 (학습된 모델만 있으면 됨)
- 변환 속도 빠르고 유지보수 편함
- 오차 작고 안정적
단점
- 최적화 수준 낮음 (속도 및 사이즈 감소 제한적)
- 실시간 고성능 GPU 추론에는 크게 도움 안 될 수 있음
ONNX 정적 양자화 (Static Quantization aka QDQ)
특징
- 가중치와 활성값 모두 INT8로 변환
- 캘리브레이션 데이터 필요 (양자화 범위 추정 위함)
- QDQ (Quant-DeQuant 노드 삽입) 방식으로 모델 바뀜
장점
- 동적 양자화보다 작고 빠르고 효율적
- GPU에서 더 나은 속도 개선 가능 (특히 TensorRT 사용 시)
단점
- 캘리브레이션 데이터 준비 필요
- 정밀도 손실 가능성 있음 (보정 가능)
실시간 PAR 프로젝트에서는 추론 속도와 효율성이 중요 -> 정적 양자화가 더 적합
하지만 캘리브레이션 데이터 없는 경우 동적 양자화 먼저 적용하고
추후 캘리브레이션 데이터 수집해 정적 양자화로 전환 가능
TensorRT로 INT8 양자화 하려면 반드시 캘리브레이션 데이터 필요
INT8 양자화는 모델의 활성값(activation) 분포를 미리 알아야 정밀도 잃지 않고 양자화할 수 있음
그러려면 실제 입력값 몇 개를 넣어보면서 range를 추정해야 함 -> Calibration
캘리브레이션 데이터 없는 경우 FP16 먼저 사용해 볼 수 있음
- FP16은 양자화가 아니라 정밀도 축소(precision reduction)
- 하지만 효과는 양자화처럼 속도 향상, 메모리 절약 가능
- FP16은 대부분의 GPU에서 하드웨어 가속 지원 때문
- INT8은 정수 연산 -> 더 빠르지만 정확도 손실 많음
FP16 + ONNX 조합
단순히 정밀도만 낮추는 것보다 더 많은 실제 성능 최적화(= inference 속도 향상) 끌어낼 수 있음
ONNX는 프레임워크 독립적인 표준 포맷
- PyTorch 모델은 PyTorch에서만 돌릴 수 있음
- ONNX로 바꾸면 ONNX Runtime이나 TensorRT 같은 최적화된 런타임에서 실행 가능
- 내부적으로 연산 그래프를 더 잘 최적화해 줌 (불필요한 연산 제거, 병렬화 등)
FP16만 하면 GPU에서 float 연산 속도만 개선됨
- 그냥 model.half() 쓰는 건 PyTorch 수준에서만 정밀도 낮추는 것
ONNX로 바꾸면 런타임 최적화 적용됨
- ONNX Runtime은 내부적으로 FP16 연산으로 자동 fusion 해주고,
- TensorRT는 FP16 전용 path로 최적화된 커널 씀
- PyTorch → FP16만 적용한 모델보다 더 빠르고 가볍게 작동
진행 순서
- PyTorch FP32 → baseline (완료)
- PyTorch FP16 → 정밀도 향상
- ONNX FP32 → 구조 최적화
- ONNX FP16 → 구조 + 정밀도 최적화
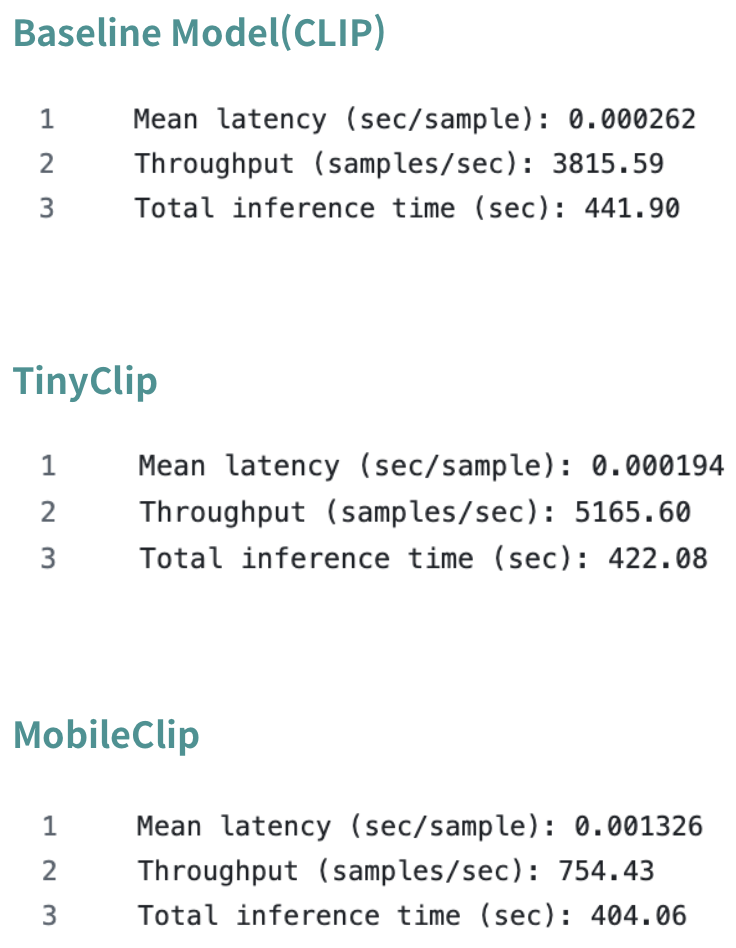
PyTorch FP16
CLIP

TinyClip

MobileClip


- 일부 연산은 FP16으로 바꿔도 GPU에서 최적화가 제대로 안 되면 속도가 별 차이 없거나 느려짐
- CLIP이나 TinyCLIP처럼 복잡한 구조는 FP16 최적화 효과 덜함
-> FP16은 무조건 빠른 게 아니라 조건이 맞을 때만 빠름
ONNX FP32
CLIP

TinyClip

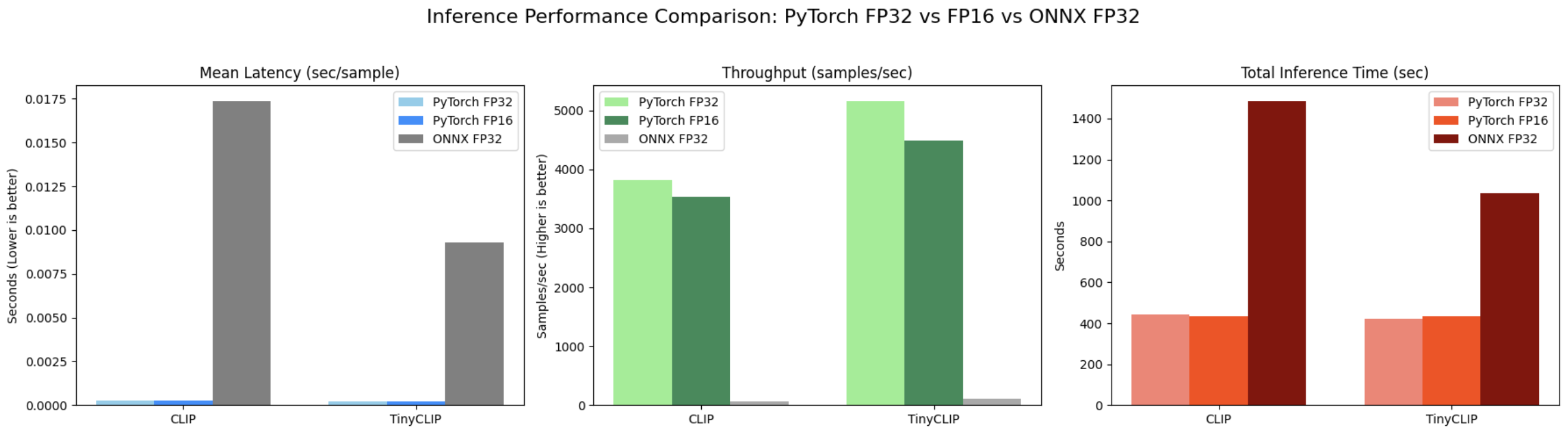
TensorRT 같은 최적화 엔진 없이 ONNX만 뽑아서 쓰면 성능 향상 거의 없고 오히려 손해
ONNX FP16
CLIP

어.. 이건 진짜 아닌 거 같아서 취소 (너무너무 느림: 베이스라인 모델의 7배정도)
지금까지 요약
목표: 실시간 PAR (Pedestrian Attribute Recognition) 성능 손실 없이 모델 경량화
대상: 이미지 인코더 위주
조건:
- 현재 캘리브레이션 데이터 없음 → 정적 양자화 불가
- 텍스트 인코더는 상대적으로 영향 적음 → 제외
- 실시간 속도 필요 → FPS, latency 민감
시도한 것
| PyTorch FP32 | ✔ baseline, 가장 안정적 |
| PyTorch FP16 | ❌ 정밀도 낮추기 → 성능 미미 or 악화 |
| ONNX FP32, ONNX FP16 | ❌ 변환 + 추론 → 오히려 느려짐 |
-> 정밀도만 낮추는 방식은 별 의미가 없음!
진행 예정: 캘리브레이션 데이터 추출해 정적 양자화 실험

- 200~1000장 추출
- TinyCLIP, CLIP에 적용 → INT8 quant ONNX 모델 추론
https://huggingface.co/docs/optimum/en/concept_guides/quantization
Quantization
Quantization is a technique to reduce the computational and memory costs of running inference by representing the weights and activations with low-precision data types like 8-bit integer (int8) instead of the usual 32-bit floating point (float32). Reducing
huggingface.co
https://www.geeksforgeeks.org/quantization-in-deep-learning/?ref=next_article
Quantization in Deep Learning - GeeksforGeeks
Your All-in-One Learning Portal: GeeksforGeeks is a comprehensive educational platform that empowers learners across domains-spanning computer science and programming, school education, upskilling, commerce, software tools, competitive exams, and more.
www.geeksforgeeks.org
'Capstone' 카테고리의 다른 글
| [ Meeting ] 5월 4주차 - 그래도 Quantization ..! (0) | 2025.05.25 |
|---|---|
| [ Meeting ] 5월 3주차 - use pre-quantization model (0) | 2025.05.20 |
| 이쯤에서 다시 보는 목표 (0) | 2025.05.09 |
| [ Meeting ] 5월 1주차 - Baseline 측정(PyTorch FP32) (0) | 2025.05.05 |
| [ Meeting ] 4월 3주차 - Quantized clip 조사, Baseline 성능 측정 (0) | 2025.04.17 |



