로드맵에 기반해 이번 주차 일정을 진행했다.
이제 정말 시간을 많이 써야한다. 진짜로 !

PAR(Pedestrian attribution recognition)에 적합한 경량 CLIP 모델을 선정했다.
CLIP를 Baseline Model로 하고,
TinyCLIP, CLIP-BERT, MobileCLIP 경량 CLIP 모델로 실험하기로 했다.
CLIP Text Enconder -> LLM 부분이라고 부르지 않음. 그냥 CLIP의 Text Enconder
CLIP은 image가 main.
LLM은 image는 딱히 X
그래서 PAR을 CLIP/ LLM 중 어떤 타입으로 해야 하는지?
-> 이래서 이 프로젝트에 LLM이 사용되는지 물어보신 것
내가 자꾸 CLIP의 LLM 부분을 경량화한다고 하니까.. ㅇㅅㅇ
그럼 CLIP의 Text Enconder 를 경령화하는 건 말이 되나?
CLIP과 LLM 중 각자 가벼운 모델로 바꿔보고 try ..!

이전에 CLIP, TinyCLIP에 대해 인퍼런스 시간 측정한 게 이상해서 (한 이미지에 대해 실험했는데, TinyCLIP이 더 느림)
이제 이 프로젝트에서 사용할 MSP60K 데이터셋의 랜덤 이미지에 대해 제대로 측정해보려고 했다.
GPU 로딩시간 등 때문에 시간 오래 걸릴 수도 있음 -> batch 건너뛰고 측정하던지
다른 사람은 어떻게 하는지 보기.
인퍼런스 시간 느리면 평균값, 중앙값 잰다던지..
빠르게 숫자 뽑아보기
CLIP 성능, mobile CLIP 성능은 이 정도..
그리고 CLIP+LLM은 이 정도 ~~

역시 감이 안잡힐 때는 데이터셋 먼저 까보고 바로 실험에 들어가야 한ㄷㅏ..
1~2월 중 이미 끝냈어야 할 작업인데 너무 길게 끌었다.
merged_labels.json 파일 내용은 단순히 속성에 대한 값들!
0: 이 속성 없음
1: 이 속성 있음
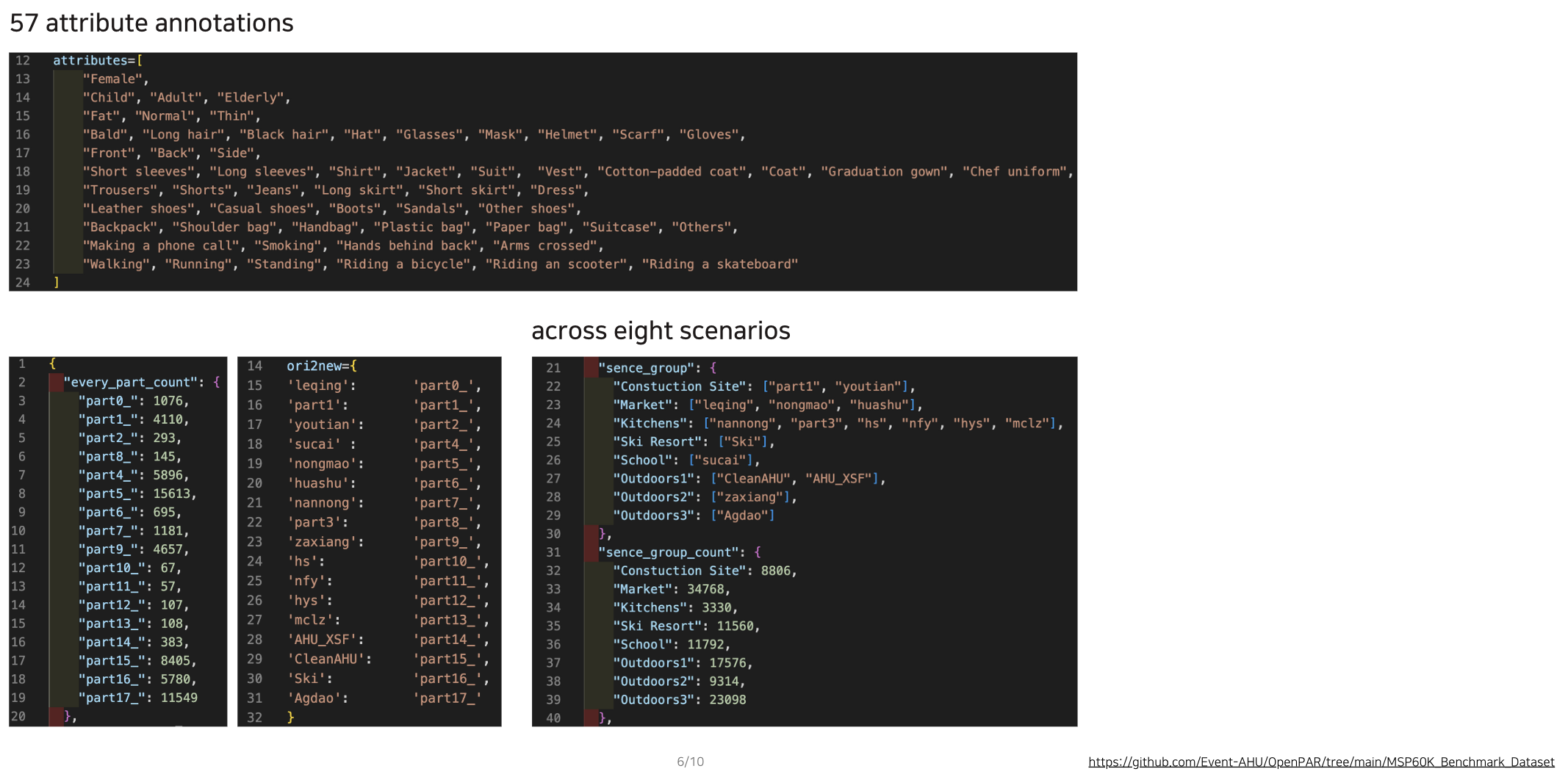
그리고 속성(annotation) 값 모아둔 파일은 따로 있음 (이 구조라면 당연함)
추가로,
1. pickle 파일은 무엇을 담고 있는 건지 알아봐야 함
2. degraded_images는 무엇을 위해 존재하는 걸까? 이미지 픽셀과 화소를 줄여 메모리 사용량 감소를 위함일까?
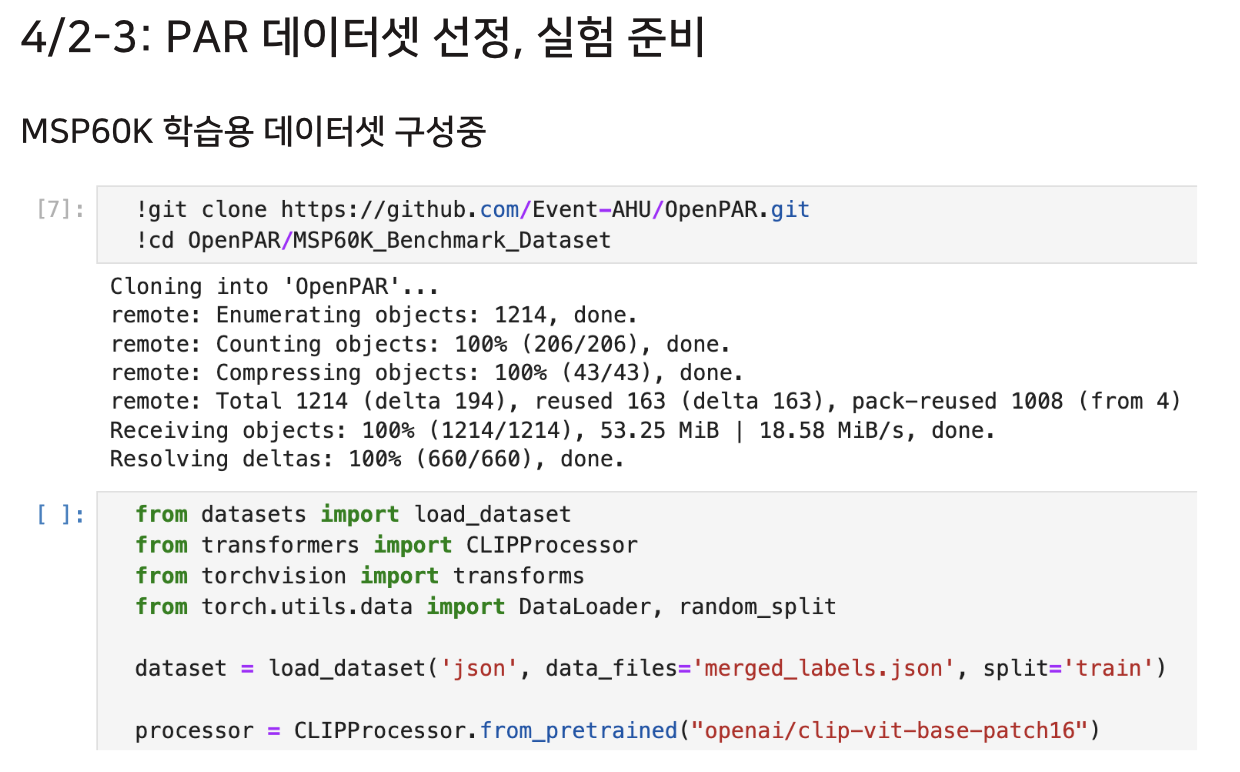
학습 데이터셋 구성해서 이제 돌려봐야해 (!!)

4월 1~2주: 모델 바꿔봤다 정도는 해야 함(수치)
4월 3~4주: 남들이 했던 거 + 세팅 => 얘를 뭘로 바꿔보자.
-> 혼자 할 수 있는 거 speedy하게 진행
5월: 성능 보정
'Capstone' 카테고리의 다른 글
| [ Meeting ] 4월 3주차 - Quantized clip 조사, Baseline 성능 측정 (0) | 2025.04.17 |
|---|---|
| [ Meeting ] 4월 2주차 - 데이터셋 구성, 모델별 Inference Time 측정 (0) | 2025.04.11 |
| [ Meeting ] 3월 3, 4주차 - Roadmap, 논문리뷰 (0) | 2025.04.07 |
| [ Meeting ] 3월 2주차 - 인퍼런스 시간, Paper (0) | 2025.03.19 |
| CLIP, TinyCLIP 인퍼런스 시간 체크 (0) | 2025.03.18 |



