논문 리뷰할 때는 주장과 근거가 명확한지 본다
방법론과 이론 증명, 실험, 평가가 잘 되어 있는지 본다
그에 따른 증거가 정확한지 본다
논문 리딩할 때도 <구조화>해서 보자
Table 1에서 나온 논문의 abstract 정도 읽어보고 현재 논문과 뭐가 얼마나 어떻게 다른지 확인하기

1. Wen & Li (2021):
• Training Dynamics: Wen & Li는 training dynamics에 대해 다룹니다. 이들은 contrastive learning의 훈련 동역학을 설명하며, ReLU 네트워크를 사용하여 sparse features를 학습하는 과정을 이론적으로 제시합니다.
2. Nakada et al. (2023):
• Training Dynamics: Nakada et al.는 training dynamics를 linear 모델에 대해 다룹니다. MMCL과 asymmetric matrix factorization의 연결을 설명하면서, contrastive learning에서의 feature alignment와 generalization을 연구합니다.
• Zero-shot Generalization: Zero-shot 성능에 대해서 연구하고 있습니다.
3. Chen et al. (2024):
• Training Dynamics: 이 논문은 contrastive learning에서 transferable representation learning을 다루고 있으며, CLIP 모델을 분석합니다.
• Zero-shot Generalization: Zero-shot 성능을 다루며, CLIP이 어떻게 zero-shot을 잘 수행하는지 설명합니다.
• Synthetic Text Captions: Synthetic captions에 대한 언급은 없지만, CLIP이 multimodal 데이터를 사용하여 좋은 성능을 낸다고 설명합니다.
• Multi-modal: Multi-modal 학습을 다루며, CLIP의 vision-language 접근 방식을 설명합니다.
4. Lee et al. (2021):
• Training Dynamics: Self-supervised contrastive learning을 다루며, pretext tasks를 활용하여 representation learning을 개선하는 방법을 제시합니다.
• Zero-shot Generalization: Zero-shot과 관련된 이론적인 접근을 제공합니다.
5. Zhang et al. (2023a):
• Training Dynamics: MMCL의 feature alignment 및 multi-modal contrastive learning을 다룹니다.
• Zero-shot Generalization: Zero-shot 성능을 다룹니다.
• Synthetic Text Captions: 이 논문은 synthetic captions을 다루지 않지만, contrastive learning에서 multi-modal 데이터 사용에 대한 설명이 있습니다.
• Multi-modal: Multi-modal 데이터를 활용하는 MMCL을 다룹니다.
이 논문과의 비교:
• 이 논문은 synthetic text captions을 사용하여 feature alignment을 개선하고, contrastive learning의 zero-shot generalization 성능을 향상시키는 방법을 다룹니다.
• Wen & Li (2021), Nakada et al. (2023), Zhang et al. (2023a) 논문은 contrastive learning의 training dynamics와 multi-modal 접근에 대해 다루고 있으며, 이 논문과 비교될 수 있습니다. 그러나 이 논문은 synthetic captions의 사용을 강조하고 있다는 점에서 차별화됩니다.
• Chen et al. (2024)는 CLIP 모델을 분석하며 zero-shot generalization 성능을 다루고 있지만, synthetic captions과는 관련이 없습니다.
• Lee et al. (2021)는 self-supervised 및 pretext tasks에 관한 논의로, synthetic captions과의 직접적인 연관은 없지만 generalization을 다룬다는 점에서 연관이 있습니다.
이 논문에서 제시하는 "Synthetic caption"이 유의미한 내용을 담고 있는지?
- 왜 이름이 <합성> 캡션이지? (이미지-(이미지 설명이 잘못된)텍스트 쌍 -> 이미지-(이미지 설명이 제대로 된)텍스트 쌍 이렇게 바꾸는 건데 왜 <합성> 이라는 이름을 채택했냐는 거
ITCP할 때 코사인 유사도를 사용한다고 하는데 ㅡ이미지와 텍스트 간 유사도 최대화하면서 negative쌍의 유사도 최소화하는 게 목표ㅡ 코사인 유사도는 기존 연구들에서도 대부분 사용되는 개념이 아닌가
코사인 유사도는 이미지와 텍스트 간의 유사도를 측정하는 기존의 널리 사용되는 개념입니다. 이 논문에서는 synthetic captions을 사용하여 contrastive learning의 feature alignment 성능을 개선하는 과정에서 이 개념을 그대로 적용하고 있습니다. 코사인 유사도는 positive 쌍의 유사도를 최대화하고, negative 쌍의 유사도를 최소화하는 데 중요한 역할을 하며, 이는 이미지와 텍스트 간의 잘 정렬된 표현을 학습하는 데 기여합니다.
nonconvex를 강조하는데 이게 여기서 중요한 건지
Training Dynamics (훈련 동역학)
• Training dynamics에서 nonconvex와 nonlinear의 특성이 중요한 이유는, nonlinear 네트워크가 복잡한 특징을 학습하는 데 필요한 모델의 동적 특성을 정의하는 데 핵심 역할을 하기 때문입니다. 논문은 contrastive loss가 nonlinear activation을 사용하여 어떻게 training dynamics에 영향을 미치는지 설명합니다. nonlinear 모델은 이미지-텍스트 정렬을 향상시키는 데 중요한 역할을 하며, nonconvex 문제에서 적절한 최적화가 이루어질 수 있도록 돕습니다.
Feature Alignment
• Feature alignment를 개선하기 위해 synthetic captions을 사용하는데, nonlinear 모델은 더 복잡한 패턴을 학습하면서 더 나은 feature alignment를 달성할 수 있습니다. 특히, nonconvex 손실 함수가 SGD와 같은 최적화 기법을 통해 최적화될 때 spurious correlations을 줄이고 feature alignment를 개선할 수 있습니다.
3. 결론: Nonconvex와 Nonlinear의 역할
• 이 논문에서 nonconvex와 nonlinear는 단순히 수학적 특성에 대한 언급이 아니라, contrastive learning에서의 효과적인 학습과 일반화에 실질적인 영향을 미치는 중요한 요소입니다. nonlinear activation을 사용한 nonconvex 최적화 과정은 spurious correlations을 줄이고, synthetic captions을 통해 image-text feature alignment을 개선하는 데 중요한 역할을 합니다.
3. 기술적 조건 에서 간단한 모델이지만 <비선형성 문제로 인해 학습 분석 어려운 부분을 해결하는 데에 도움이 됐다>고 하는데, 비선형성이 이전 연구나 지금 연구에 어떤 문제를 야기했는지?
이 논문에서 SGD는 nonlinear 모델에서 nonconvex 손실 함수를 최적화하는 데 중요한 역할을 합니다. 논문은 SGD를 활용하여 synthetic captions을 통한 feature alignment의 최적화를 다루고 있으며, spurious correlations을 줄이는 데 SGD가 어떻게 도움이 되는지를 설명하고 있습니다.
• 차별점은 이 논문이 nonlinear 모델을 contrastive learning에 적용하여 feature alignment를 개선하는 과정에서 SGD를 사용하는 방식에 대한 이론적 분석을 제공한다는 점입니다. 또한, synthetic captions을 사용하여 이미지-텍스트 정렬을 개선하는 데 SGD가 어떻게 적용되는지 이론적으로 설명하고 있습니다.
3.2 Data Formulation for ITCP 에서 sparse coding은 학습 데이터를 더 정밀하게 다루도록 도와준다고 하는데, 이런 이미지-텍스트 쌍에 대해 구체적인 설정은 왜 필요한 거야? 구체적으로 설정하고 다 입맛에 맞추면 당연히 결과 잘 나오는 거 아닌가
아니면 sparse coding을 이 연구에만 사용하자는 게 아니라 정말 "기술" 하나로서 제안하는 건가
• 이미지-텍스트 쌍에서는 각 모달리티(이미지, 텍스트)가 서로 다른 특성을 가지고 있기 때문에, 이를 정확하게 표현하고 정렬하는 데 어려움이 있을 수 있습니다. 특히 noisy하거나 부정확한 이미지-텍스트 쌍이 있을 경우, sparse coding을 활용하여 희소한 특징들만을 학습하면서 필요 없는 잡음을 줄이고, 실제 중요한 정보만을 잘 학습할 수 있도록 돕습니다.
• Sparse coding은 불필요한 정보(예: 잘못된 이미지-텍스트 쌍의 설명 등)를 제거하고, 필요한 정보만을 학습할 수 있게 해주는 방법입니다. 이렇게 함으로써, 학습 데이터에 불필요한 잡음이 포함되지 않도록 하여 모델의 성능을 향상시킬 수 있습니다.
• 구체적인 설정이 필요한 이유는, 이미지-텍스트 쌍에서 단순히 희소성을 적용하는 것이 아니라, 이 두 모달리티 간의 관계를 잘 표현할 수 있는 특징을 추출해야 하기 때문입니다. 즉, 모달리티 간의 차이나 불일치가 있을 수 있기 때문에, 각각의 이미지-텍스트 쌍에서 어떤 특징을 강조하고, 어떤 특징은 배제할 것인지를 정의하는과정이 필요합니다.
• 예를 들어, 이 논문에서 sparse coding은 이미지-텍스트 쌍에 적합한 특징을 찾아내고, 이를 feature alignment를 통해 모델의 학습 성능을 향상시키는 방법론으로 사용되고 있습니다. 이런 설정이 없다면, 모델은 비효율적인 학습을 할 수 있습니다.
Assuumption 3.4, 3.5 이런 파트가 전반적으로 이해가 안감
고품질 이미지-텍스트쌍을 다루기 위한 가정ㅡ이미지-텍스트가 완전히 일치하는 특성만 사용할 때ㅡ이라던가 저품질 데이터셋에서도 학습 과정에서 spurious data 처리할 수 있도록 함 -> 요런 건 왜 써 놓은 거지
Synthetic caption의 품질을 정의하는 확률 분포가 나와있는데, 특정 이미지 특징이 텍스트 특징과 일치할 확률 나타낸다고 함 -> 잘못된 매칭 방지하는 데에 중요하다고 하는데 이게 그래서 어쩐다고.. 이게 너네가 제안하는 "기술"임?
Assumptions 3.4와 3.5는 sparse coding과 synthetic captions을 사용하여 feature alignment을 개선하는데 중요한 역할을 합니다. Synthetic captions은 이미지-텍스트 간의 매칭을 더 정확하게 만들고, 이를 통해 contrastive learning에서 spurious correlations을 줄이고, zero-shot generalization 성능을 향상시키는 기술적 접근으로 제안됩니다.
2.2 Downstream tasks 에서 wen이 2021에 한 연구에서처럼 downstream regression이나 binary classification 기법을 사용하지 않고 얘네는 K-classification을 썼다고 하는데 이게 각각 훈련된 이미지, 텍스트 인코더 통해 추출된 특징에 텍스트 인코더에 y_k를 붙인 거.
3.4 보면 이미지는 out-of domain image data 를 사용해서 이미지 벡터 x = 이미지 특징 매핑하는 행렬 * 잠재변수 + 이미지에 추가되는 노이즈 이렇게 돼 있고
텍스트는 K번째 class에 대한 텍스트 표현 = 텍스트의 매핑 행렬 + 텍스트에 추가된 노이즈 이런 식으로 돼 있음
=> 제로샷 classification에서 text prompt가 이미지 특징과 매핑되는 방식 설명
근데 이게 중요한가
• 이 과정은 이미지와 텍스트를 정확하게 매핑하여 zero-shot에서 효과적인 분류를 할 수 있도록 돕는 중요한 요소입니다. synthetic captions을 통해 feature alignment을 개선하고, 이미지와 텍스트 간의 정확한 관계를 정의하는 방식은 이 논문의 핵심 기여 중 하나입니다.
4. Main result에서 정말 당연한 얘길 하고 있음
feature alignment 위해서는 이미지-텍스트 쌍을 잘 매칭하는 게 중요 ㅇㅇ..
하지만 실무에서는 제한된 고품질의 이미지는 있는데 텍스트는 misalign된 저품질 데이터가 많아서 문제 있다고 함
그래서 우리가 어케 했냐면 ~
1. SGD가 nonconvex 학습 문제를 풀 수 있을 것임
이론 4.1보면 SGD 사용해서 비선형 모델의 학습 최적화하는 방법 나와있음
-> 네트워크가 nonlinear activations를 포함할 때의 nonconvex ITCG 문제를 해결하기 위한 이론이래..
아니 근데 진짜 비선형 모델이 뭘 잘못했는데......(?) 이게 논문에 나와있나? 이런 걸 계속 말하려면 논문에 나와야 하는데..
일단 이 이론에서는 모델이 학습 중 얻은 contrastive loss가 있는데 계속되는 학습을 통해 최적의 loss값(최적의 목표)에 근접하게 된다는 거겠지?
• 비선형 모델이 문제를 일으켰던 부분은 nonconvex 손실 함수로 인해 최적화가 어려워지는 점입니다. 그러나 SGD는 이를 해결할 수 있는 중요한 도구로, 학습이 진행됨에 따라 최적의 손실값에 점차 수렴할 수 있게 돕습니다.
• SGD와 비선형 활성화 함수를 사용한 학습 과정은 contrastive learning에서 feature alignment를 개선하고, spurious correlations을 줄이는 데 중요한 역할을 합니다.
2. spurious correlations으로 인한 feature alignment 실패
이론 4.3보면 아니 근데 이거 진짜 당연한 내용 아니냐고 ..
훈련 데이터에서 저품질 쌍 사용하면 모델이 잘못된 특성 학습해서 feature alignment 실패할 수 있다고..
똑같은 말 반복하네
멀라 그래서 자기들이 이제 합성 캡션 활용한 ITCP 통해서 모델 성능 높이는 걸 보여주겠대
이론 4.3에서 spurious correlations이 feature alignment 실패를 일으킬 수 있다는 내용은 기본적인 사실을 다시 강조하고 있으며, 이 논문은 그 문제를 해결하기 위해 synthetic captions을 활용한 ITCP 방법을 제안하고 있습니다. 합성 캡션은 정확한 이미지-텍스트 매칭을 유도하고, feature alignment를 개선하는 데 중요한 역할을 하며, 이는 모델 성능 향상에 기여할 수 있다는 것이 논문의 핵심입니다.
3. 자기들이 제안한 합성 데이터에 대해서는 feature alignment가 성공적
-> 합성 캡션을 통해 spurious correlations 제거되고 모델의 feature alignment 개선됨
이거 이론(18) 제대로 증명된 건지 알고 싶어. 이론을 검증해줘.

이론 4.5에서는 이미지와 텍스트의 특징을 주요 특징 세트(각각 M_j, H_j)에 맞춰 학습하도록 한다고 설명하고 있습니다. 그리고 neuron pair (w_i, v_i)가 주로 학습하는 특징이 무엇인지, 또 그것들이 어떻게 정렬(feature alignment)되는지를 다룹니다.
• w_i와 v_i는 각각 이미지 특징과 텍스트 특징을 나타내며, 이들이 어떻게 주로 학습되는지를 설명합니다.
• w_i는 주로 M_j와 H_j에 의해 학습되며, M_j와 H_j는 이미지와 텍스트의 주된 특징입니다.
• 그 외에 M_j와 H_j 외의 다른 특징은 작은 기여만 하며, feature alignment가 올바르게 이루어지도록 모델이 학습하게 됩니다.
• α_i,j, β_i,j, γ_i,j는 각 뉴런이 학습하는 특징의 비율이나 강도를 나타내는 계수들입니다. 이 계수들은 L2 노름을 기준으로 정의되며, 특정 조건 하에 학습되는 특징을 강조합니다.
이론 4.5는 synthetic captions을 사용하여 feature alignment를 성공적으로 개선할 수 있다는 이론적 주장에 대해, 이미지와 텍스트의 특징을 효율적으로 학습하고 정렬할 수 있다는 수학적 모델을 제공합니다. 이 이론은 합성 캡션이 spurious correlations을 줄이고, feature alignment를 개선하는 데 중요한 역할을 한다는 주장을 뒷받침합니다.
5.1 데이터, 파라미터 어떻게 설정해서 실험한 건지 정리해두기
이 a, b, c 표 뭐임 x, y축 구성을 어떻게 한 거임!
그리고 그래프에서 spurious correlations가 뭘 어떻게 컨트롤 했는지 알아보기
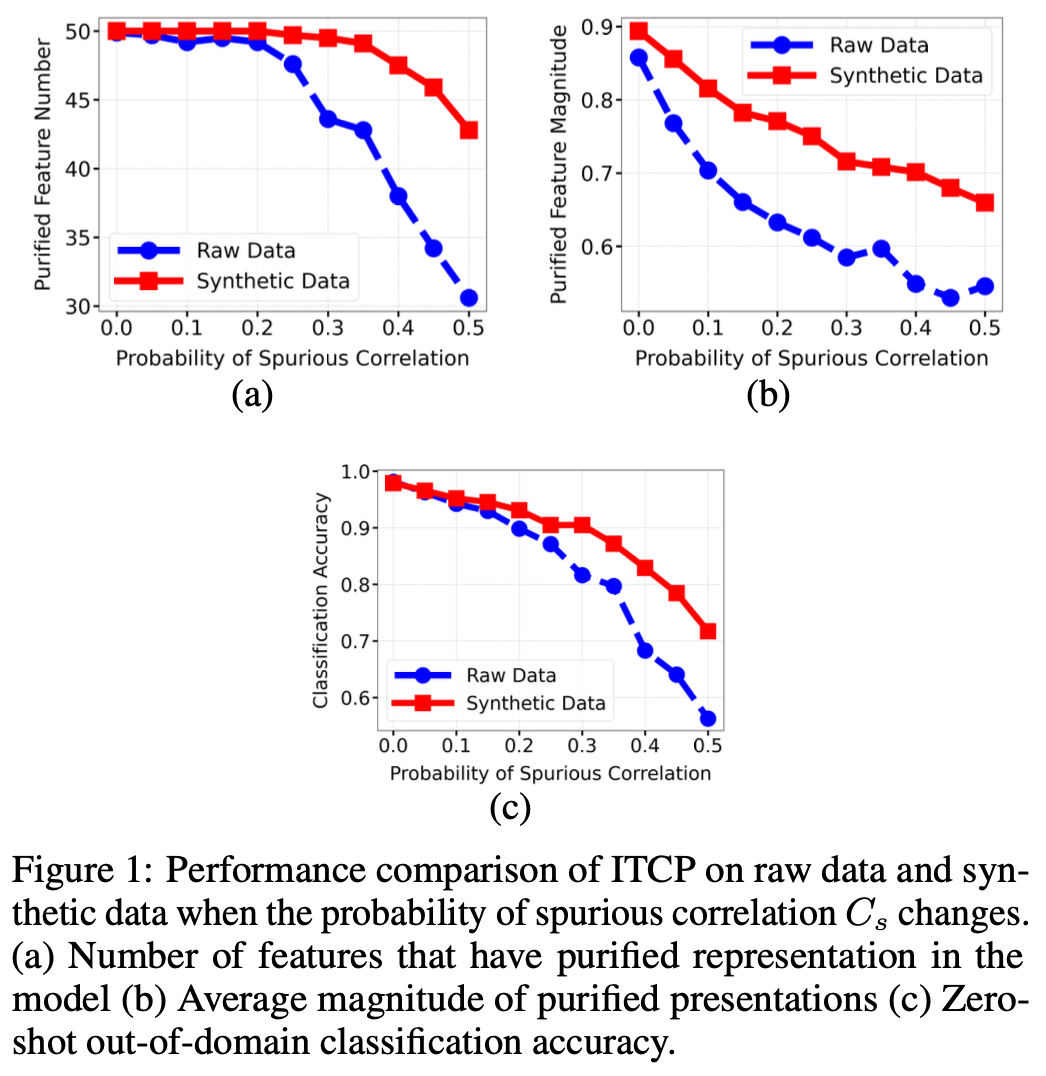
실험 데이터 설정:
• d1 = 2500: 데이터의 차원 수 (즉, 이미지나 텍스트의 특징 공간 차원).
• d = 50: d1 차원의 하위 차원. 이 값은 데이터의 특징 벡터가 매핑될 공간을 의미할 수 있습니다.
• |Sw| = 5000: 훈련 데이터의 크기 (고품질 데이터셋).
• |Sh| = 1000: 훈련 데이터의 크기 (저품질 데이터셋).
a, b, c 그래프 설명:
그래프 a: Purified Feature Number (정화된 특성의 개수)
• x축: Spurious Correlation의 확률 (C_s) (이 값은 spurious correlations이 얼마나 포함되어 있는지를 나타냅니다).
• y축: Purified Feature Number (정화된 특성 수).
• Synthetic Data(합성 데이터)와 Raw Data(원본 데이터)의 차이를 비교합니다.
그래프 b: Purified Feature Magnitude (정화된 특성의 크기)
• x축: Spurious Correlation의 확률 (C_s).
• y축: Purified Feature Magnitude (정화된 특성의 크기).
• Synthetic Data를 사용하면 Raw Data에 비해 feature magnitude가 더 커지는 경향을 보입니다.
그래프 c: Zero-shot Classification Accuracy (제로샷 분류 정확도)
• x축: Spurious Correlation의 확률 (C_s).
• y축: Zero-shot Classification Accuracy.
• Synthetic Data를 사용한 모델이 Raw Data를 사용한 모델보다 더 높은 제로샷 정확도를 보입니다.
Spurious Correlation의 컨트롤 방식:
• Spurious correlations는 잘못된 이미지-텍스트 매칭이나 잡음을 의미합니다. 이 값은 0에서 0.5까지 변화하며, 0에 가까울수록 이미지와 텍스트 간의 정렬이 정확해지고, 0.5에 가까울수록 더 많은 잘못된 매칭이 포함됩니다.
• 이 논문에서는 합성 캡션을 사용하여 spurious correlations을 줄이고 모델이 보다 정확한 특징을 학습할 수 있도록 돕습니다. Synthetic Data를 사용하면 spurious correlations이 적은 데이터에서 feature alignment가 개선되며, 그 결과 제로샷 분류 성능도 향상됩니다.
figure2가 뭐 어떤 걸 보여주려고 그려진 그림인지도 모르겠음
0.0부터 0.7까지 이어지게 그려놓은 건가? 그럼 그림 하나로 만들 수 있지 않나?
0.05랑 0.7에 집중되게 나온 이유는 데이터의 노이즈 때문이라 함
-> 그래서 결국은 합성 데이터로 학습 시킨 뉴런들이 더 집중된 구역을 가진다는 것을 말하고 싶었다고? 이게 맞는 건가
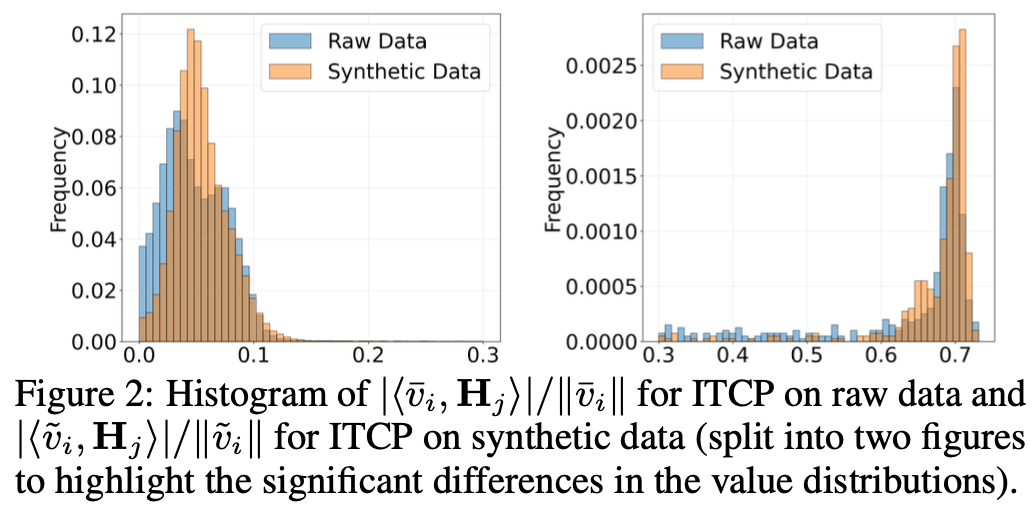
1. 그래프의 목적:
• Figure 2는 Raw Data와 Synthetic Data를 사용하여 훈련된 뉴런들의 특징 추출 값이 어떻게 달라지는지 비교하는 히스토그램을 나타냅니다.
• 각 히스토그램은 |〈ṽᵢ, Hⱼ〉| / ||ṽᵢ|| 값을 보여주며, 이는 이미지 특징과 텍스트 특징의 정렬 정도를 나타냅니다.
2. 분포의 차이:
• Synthetic Data로 훈련한 뉴런들은 특징 값이 집중된 분포를 보입니다. 주로 값이 0.05와 0.7에 집중되는 경향을 보이는데, 이는 데이터의 노이즈로 인해 일부 변동이 있지만, 합성 데이터를 사용하여 feature alignment가 더 잘 이루어진다는 증거입니다.
• 반면, Raw Data는 분포가 더 넓게 퍼져 있으며, 정렬이 덜 이루어졌다고 볼 수 있습니다.
3. 노이즈와 집중:
• 0.05와 0.7에 값이 집중되는 이유는 데이터의 노이즈 때문이라는 설명입니다. 이는 학습 데이터에 잡음이 포함되어 있어서, 이 값들이 나타날 수 있다는 것을 의미합니다. 즉, 특징 값의 집중이 합성 데이터에서는 더 잘 정렬된 상태에서 이루어진다는 점을 강조하려는 의도입니다.
5.2 실험에서 Transformer 썼다는 거 같은데? 맞아?
BLIP ViT-B/16 200M 파라미터 -> 이건 14M개 이미지에 대해 사전학습된 Vision language 모델임
(사람 수작업 데이터 조금과 웹에서 가져온 이미지-텍스트 쌍이 대부분인 모델)
=> 이 모델은 이전의 ALBEF 모델의 성능 향상된 모델임(같은 모델 아키텍처와 학습 데이터 사용)
차이점은 ALBEF는 raw data에 ITCP로 학습시키고
BLIP은 합성 캡션 사용한 데이터에 ITCP로 학습시킨다는 것.
=> 다른 사람 실험 결과 합성 캡션 사용한 데이터로 한 BLIP이 ALBEF의 성능을 넘어 일반화 성능이 향상됨
5.2 실험과 모델에 대한 설명
BLIP (Vision-Language Pre-training) 모델은 ViT-B/16 아키텍처를 사용하며, 200M 파라미터를 가진 모델로, 14M 개의 이미지에 대해 사전 훈련된 Vision-Language 모델입니다. 이 모델은 ALBEF 모델의 향상된 버전으로, ALBEF와 동일한 아키텍처와 학습 데이터를 사용하지만, 합성 캡션을 사용하여 훈련을 시킨다는 점에서 차이가 있습니다.
ALBEF 모델은 Raw Data를 사용하여 ITCP로 학습되지만, BLIP 모델은 합성 캡션을 사용하여 학습됩니다. 합성 캡션을 사용한 BLIP 모델이 ALBEF 모델보다 일반화 성능에서 뛰어난 결과를 보였다고 합니다. 특히 feature alignment가 개선된 결과를 보이며, 모델이 더 정확한 특징을 학습하는 모습을 보여주고 있습니다.
이 논문에서는 Transformer 아키텍처를 사용한 실험을 직접적으로 다룬 내용이 5.2 실험 부분에서 언급됩니다. 여기에서 BLIP 모델과 ALBEF 모델을 비교하고 있으며, 두 모델 모두 Transformer 기반의 아키텍처를 사용한다고 명시되어 있습니다. 특히 BLIP 모델은 Transformer를 기반으로 한 ViT (Vision Transformer) 모델을 사용하고 있으며, ALBEF 모델도 비슷한 방식으로 Transformer 아키텍처를 사용하고 있습니다.
1. COCO 데이터셋 카테고리 분류 성능 강화
BLIP과 ALBEF 비교하니 BLIP는 클래스 별로 비교적 잘 구분되었고 ALBEF는 overlap되는 부분이 많았음
-> 합성 데이터는 feature alignment를 향상시키는 결과 보임
Image-Raw web caption 사이의 코사인 유사도 계산한 거 -> mean값 0.24
Image-BLIP에서 생성된 합성 캡션 사이의 코사인 유사도 계산한 거 -> mean값 0.26
=> 유사도 0.2 정도 오르긴 했는데 이 정도로도 성능 많이 향상되나 보네?
이들은 비선형 함수를 가진 비전 랭귀지 모델에서의 대조 학습에서의 학습 동적성을 이론적으로 분석하고 싶었다 요고
저자들이 잘했다 하는 거 : feature alignment와 제로샷 성능을 향상 시키는 것에서의 합성 캡션의 중요한 역할을 찾은 것
앞으로 할 거 : Transformer 아키텍처에서 대조 학습 분석을 포함하는 것, 더 복잡한 task에 대해 접근해보는 것


